Versions de Java
Commençons par un petit historique des versions de Java et de Java SE.
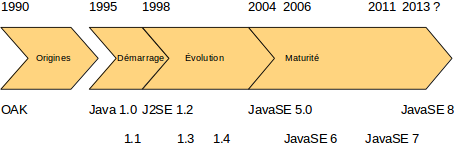
La première chose qu’on constate, c’est le ralentissement du rythme des sorties. Les cinq premières versions étaient livrées tous les dix-huit mois, avec parfois des versions mineures intermédiaires. C’était aussi le temps des acrobaties marketing ; Java 2 SE version 1.4.2, c’est franchement mauvais en terme de lisibilité.
La version 5 a marqué un véritable tournant. Pour le nom, déjà : on passe de J2SE à Java SE ; fini le 2 sans signification. Fini aussi le 1.x ; vus les changements entre la 1.0 et cette potentielle 1.5, une version 2 aurait été un langage totalement différent ; autant changer de nom dans ce cas. Finies aussi les versions mineures. Il n’y aura pas de version 5.1. Enfin sur le contenu, cette version 5 a été très importante pour rendre le langage Java plus pratique. On se rappellera que les generics, les types Enum et les annotations datent de cette version.
La suite est moins enthousiasmante. Deux ans pour une version 6 sans grand relief, puis le silence. Quatre ans et demi sans nouvelle version ! Plusieurs causes se cumulent pour expliquer ce délai. La première est la mise en open source du JDK, avec le démarrage du projet OpenJDK peu de temps après la sortie de la version 6. Ce projet s’est accompagné d’un changement de politique entre le JDK et la spécification. Dorénavant, le développement public du JDK précède la rédaction de la spécification. Enfin, dernière explication, et pas des moindres, le rachat de Sun Microsystems par Oracle et le délai imposé par l’Union Européenne pour son enquête. Celle-ci concernait une éventuelle position dominante dans le domaine de la base de données, mais a beaucoup affecté l’évolution de Java.
Finalement, cette version 7 est là et c’est certainement le plus important, probablement plus encore que son contenu. Java is moving forward, et j’ajouterais again.
Nouveautés de Java 7
Il existe un nombre important d’articles traitant des nouveautés de Java SE 7. Ne vous enthousiasmez pas trop en les lisant car certains se basent sur les prévisions initiales de Sun qui ont été remises en question en 2010, dans le plan B d’Oracle. Celui-ci avait pour objectif de livrer une version moins ambitieuse mais suffisamment intéressante dans un délai raisonnable. Pour cela, des fonctionnalités majeures ont été reportées à la version 8 ou à plus tard encore. Donc si vous lisez un article vous présentant les closures ou la modularité en Java SE 7, vous risquez d’être déçu…
Donc pour résumer, les principales nouveautés du langage dans Java SE 7 sont :
Toutes ces nouveautés viennent du projet Coin. On trouve aussi de nouvelles API comme NIO2 et fork / join, des changements de plus bas niveau, au niveau de la sécurité et avec la nouvelle instruction InvokeDynamic, et quelques modifications mineures.
Opérateur en diamant
Cette nouvelle notation permet d’alléger le code lorsqu’on instancie une classe avec generic. Le cas classique est celui des collections :
List<MyClass> maListeOld = new ArrayLis<MyClass>();Le type contenu dans la liste est répété entre la déclaration et l’instanciation. L’opérateur en diamant évite cette redondance :
List<MyClass> maListeNew = new ArrayList<>();Les esprits chagrins prétendent que ça ne sert à rien puisque leur IDE préféré leur évite de réécrire le contenu. Mon avis est que c’est encore un cas où l’IDE servait à combler une lacune du langage, comme c’est souvent le cas.
Cette évolution est légère mais sera très souvent utile.
Strings in switch statements
Dans un premier temps, seuls les types entiers (byte, short, int, long, char) pouvaient être utilisés dans les switch, sous forme littérale ou par l’intermédiaire de constantes.
switch (month) {
case Calendar.DECEMBER :
case Calendar.JANUARY :
case Calendar.FEBRUARY :
season = Season.WINTER;
break;
...
}Avec JavaSE 5, le switch a été étendu aux types énumérés.
enum Season {
SPRING, SUMMER, FALL, WINTER;
} switch (season) {
case WINTER:
headgear = "woolly hat";
break;
...
}La version 7 apporte maintenant le support du type String.
switch (headgear) {
case "none" :
//...
break;
}Valeurs littérales formatées
Cette nouveauté paraît anecdotique, mais peut faciliter la lecture de code qui manipule des grandes valeurs littérales numériques.
Par exemple, que vaut 2365876245 ? Deux cent millions, deux milliards, vingt milliards ? La même valeur est plus lisible si elle est écrite 2_365_876_245.
Ainsi, long val = 2365876245L peut maintenant s’écrire long val = 2_365_876_245L.
Autre nouveauté, les valeurs littérales peuvent être écrites en binaire.
Jusqu’à maintenant, le décimal, l’octal et l’hexadécimal étaient supportés.
Pour écrire une valeur en binaire, il faut la préfixer par 0b.
int binaryValue = 0b011100101;Pour rappel, le préfixe pour l’hexadécimal est 0x et celui pour l’octal est 0.
Ainsi, la valeur 229 peut s’écrire sous les quatre formes suivantes :
int decimalValue = 229;
int binaryValue = 0B011100101;
int hexaValue = 0xe5;
int octalValue = 0345;[#multicatch]"> == Multi-catch
Jusqu’à maintenant, dans la structure try-catch, chaque catch ne pouvait traiter qu’un seul type d’exception. Donc c’est un traitement spécifique pour chaque type d’exception attrapée.
try {
Class.forName("org.sewatech.examples.java7.MyClass").newInstance();
//...
} catch (ClassNotFoundException e) {
System.err.printf("Problème de création de mon objet (%s)\n", e);
} catch (InstantiationException e) {
System.err.printf("Problème de création de mon objet (%s)\n", e);
} catch (IllegalAccessException e) {
System.err.printf("Problème de création de mon objet (%s)\n", e);
}On peut certes jouer avec l’héritage entre classes d’exception, mais on arrive rapidement à quelque chose comme catch(Exception ex).
Sans grand intérêt.
try {
Class.forName("org.sewatech.examples.java7.MyClass").newInstance();
//...
} catch (Exception e) {
System.err.printf("Problème de création de mon objet (%s)\n", e);
}Pour éviter ce tout-ou-rien, Java SE 7 permet maintenant de traiter plusieurs types d’exceptions, séparés par un 'pipe', pour chaque catch.
try {
Class.forName("org.sewatech.examples.java7.MyClass").newInstance();
//...
} catch (ClassNotFoundException | InstantiationException | IllegalAccessException e) {
System.err.printf("Problème de création de mon objet (%s)\n", e);
}Au passage, le rethrow est mieux géré, avec une meilleure inférence.
Très pratique, cette nouveauté ne devrait pas être tant utilisée que cela ; la faute aux frameworks comme hibernate, Spring, CDI,… qui nous aident à mieux gérer les exceptions et, surtout, à en séparer le traitement du code métier.
[#try-with-resource]" == Try-with-resources
Dans plusieurs APIs de Java, il est nécessaire de clore les ressources utilisées. C’est le cas pour JDBC ou IO et plus généralement pour celle utilisant des ressources externes. Pour éviter la fuite de ressources, il est nécessaire de mettre l’appel de la méthode de clôture dans un bloc finally. Si on ajoute à cela la gestion des exceptions, généralement validées (checked), on obtient un code très peu lisible, avec beaucoup de code qui n’a rien à voir avec l’objectif fonctionnel.
Dans l’exemple ci-dessous, on ouvre un fichier texte, qu’on lit ligne par ligne.
BufferedReader br;
try {
br = new BufferedReader(new FileReader("readme.txt"));
try {
while ((line = reader.readLine())!= null) {
System.out.println(br.readLine());
}
} catch (IOException e) {
System.err.println("Problème de lecture du fichier");
} finally {
try {
br.close();
} catch (IOException ex) {
}
}
} catch (FileNotFoundException ex) {
System.err.println("Fichier non trouvé");
}Dans cette portion, on commence par ouvrir un flux de lecture sur le fichier et gérer l’exception d’absence de fichier. Puis on lit le fichier ligne à ligne, ce qui peut provoquer une exception d’entrée-sortie. On clôt le flux dans le finally, ce qui peut provoquer une exception d’entrée-sortie qui ne doit pas être traitée sous peine de masquer l’exception de lecture. Ça fait beaucoup de code pour lire un fichier texte…
Le try-with-resource permet de déclarer la ressource à clore dans le try, ce qui en simplifie grandement la structure.
try (BufferedReader br = new BufferedReader(new FileReader("readme.txt"))) {
String line = null;
while ((line = reader.readLine())!= null) {
System.out.println(br.readLine());
}
} catch (IOException e) {
System.err.println("Problème de lecture du fichier");
}Cette notation peut être utilisée pour n’importe quelle classe qui implémente la nouvelle interface java.lang.AutoCloseable.
Manipulation de fichiers
L’API des entrées / sorties a eu droit a des modification non négligeables. Tout d’abord, les fonctionnalités de classe java.io.File sont reproduites et réparties dans les classes Path, Files, FileStore et FileSystem du package java.nio.file. Ensuite, le support des spécificités des systèmes de fichiers Posix est apporté, en particulier les permissions et les liens symboliques. Enfin, un système de notification a été ajouté.
Ces nouveautés apportent une meilleure organisation des responsabilités et permettent de simplifier certaines portions de code. Ainsi, l’exemple de lecture d’un fichier devient :
try (BufferedReader reader = Files.newBufferedReader(Paths.get("readme.txt"), UTF8)) {
String line = null;
while ((line = reader.readLine())!= null) {
System.out.println(line);
}
}NIO2 permet de simplifier encore ce code pour le cas des petits fichiers en nous évitant de manipuler le reader.
List<String> lines = Files.readAllLines(Paths.get("readme.txt"), UTF8);
for (String line: lines) {
System.out.println(line);
}Le site JTips fournit des détails sur les nouveautés de NIO2.
Conclusion
Cette version 7 était attendu de longue date, et sa sortie est une excellente nouvelle pour l’écosystème Java. Les migrations vont se faire très progressivement dans les entreprises, probablement longtemps après la fin de vie du JDK 6, en juillet 2012.
Maintenant, nous attendons impatiemment la version 8 dont le contenu devrait changer le langage beaucoup plus en profondeur, avec la modularité, les closures et d’autres nouveautés.
La priorité est aujourd’hui d’utiliser Java 7, et pour cela, Sewatech a mis ses formations à jour, en particulier Initiation au langage java et Approfondissement java.